
Summary:
Plausible but incorrect AI responses create design challenges and user distrust. Discover evidence-based UI patterns to help users identify fabrications.
What Are AI Hallucinations?
Generative AIs are well-known for their tendency to produce hallucinations — untruthful answers (or nonsense images).
A hallucination occurs when a generative AI system generates output data that seems plausible but is incorrect or nonsensical.
Hallucinations include statements that are factually false or images that have unintentional distortions (such as extra limbs added to a person). Hallucinations are often presented confidently by the AI, so humans may struggle to identify them.
Examples of AI hallucinations are everywhere. For instance, in a recent study from Columbia Journalism Review, ChatGPT falsely attributed 76% of the 200 quotes from popular journalism sites that it was asked to identify. On top of that, only in 7 out of the 153 cases where it erred did it indicate any uncertainty to the end user.
Even specialized tools aren’t immune: Stanford University’s RegLab found that custom legal AI tools from LexisNexis and Thomson Reuters produced incorrect information in at least 1 out of 6 benchmarking queries.


AI systems cannot (yet) know whether their outputs are true, so technically, hallucinations are not lies. AI is simply not concerned with truthfulness in the way that humans are. An AI’s goal is to output strings (of words, pixels, etc.) that are statistically likely for a given input (such as your prompt).
Hallucinations are a very difficult engineering problem. It is currently unknown whether eliminating them is indeed feasible with contemporary AI technologies such as transformers and LLMs.
Why Do Hallucinations Happen?
Have you ever learned the words to a song in a language you cannot understand? You might have memorized the sounds by repeating them over and over, without knowing what they mean.
Generative AI is like that to some degree. Imagine that it has learned every possible song phonetically without ever learning the language. After memorizing enough songs, it will recognize which syllables tend to go together, even though it will not understand their meaning. (This is commonly known as the “stochastic parrot” theory — which says that AI is essentially like a parrot, repeating phrases without understanding them. However, key thinkers in the AI-engineering field disagree with this theory.)
LLMs are fill-in-the-blank machines. Your prompt is the sentence before the blank space — and the generative AI is trying to figure out what the most likely next word is in the sequence. It’s based on statistics, not a deep understanding of the world. If your prompt doesn’t include a common sequence of words (or pixels or whatever you’re asking it to generate), it could be that the most likely continuation is nonsense.
Thus, generative AI is not a magical encyclopedia that can talk to you about the facts stored inside it. Its “knowledge” comes from having processed large parts of the internet (which, as you are probably aware, contains a lot of falsehoods) and learning patterns in that corpus. So, an LLM has no way to distinguish between a “hallucination” and the correct answer — in both cases, it “makes up” the answer by relying on statistics to guess the next word. Fundamentally, the problem is that LLMs don’t know when they’ve gotten something correct —- they are not structured fact databases. Given that LLMs are making everything up all the time, it’s remarkable that they are so often correct!
Bad Training Data: Garbage In, Garbage Out
Not all AI hallucinations are weird quirks of statistical models; as noted by Stephanie Lin and colleagues, they also sometimes repeat falsehoods from their training data.
Remember that these systems need really, really large amounts of training data (the older-generation GPT-3, for example, had a training data size of at least 400 billion tokens). This data will include incorrect information, opinions, sarcasm, jokes, lies, mistakes, and trolling, mixed with good information. It isn’t feasible for humans to carefully read and verify all that information, so some of it will simply be untrue.
For example, when Google’s AI Overviews feature was telling people that geologists suggest eating rocks, it didn’t make that information up from scratch; its training data included sources from all over the web. In this case, this answer came from the Onion, a well-known satirical site. What makes this example even more fascinating is that a geoscience-company website had reposted the Onion article because it thought it was funny; however, the joke was lost to the AI, which, instead, interpreted the reposting as an authority signal.
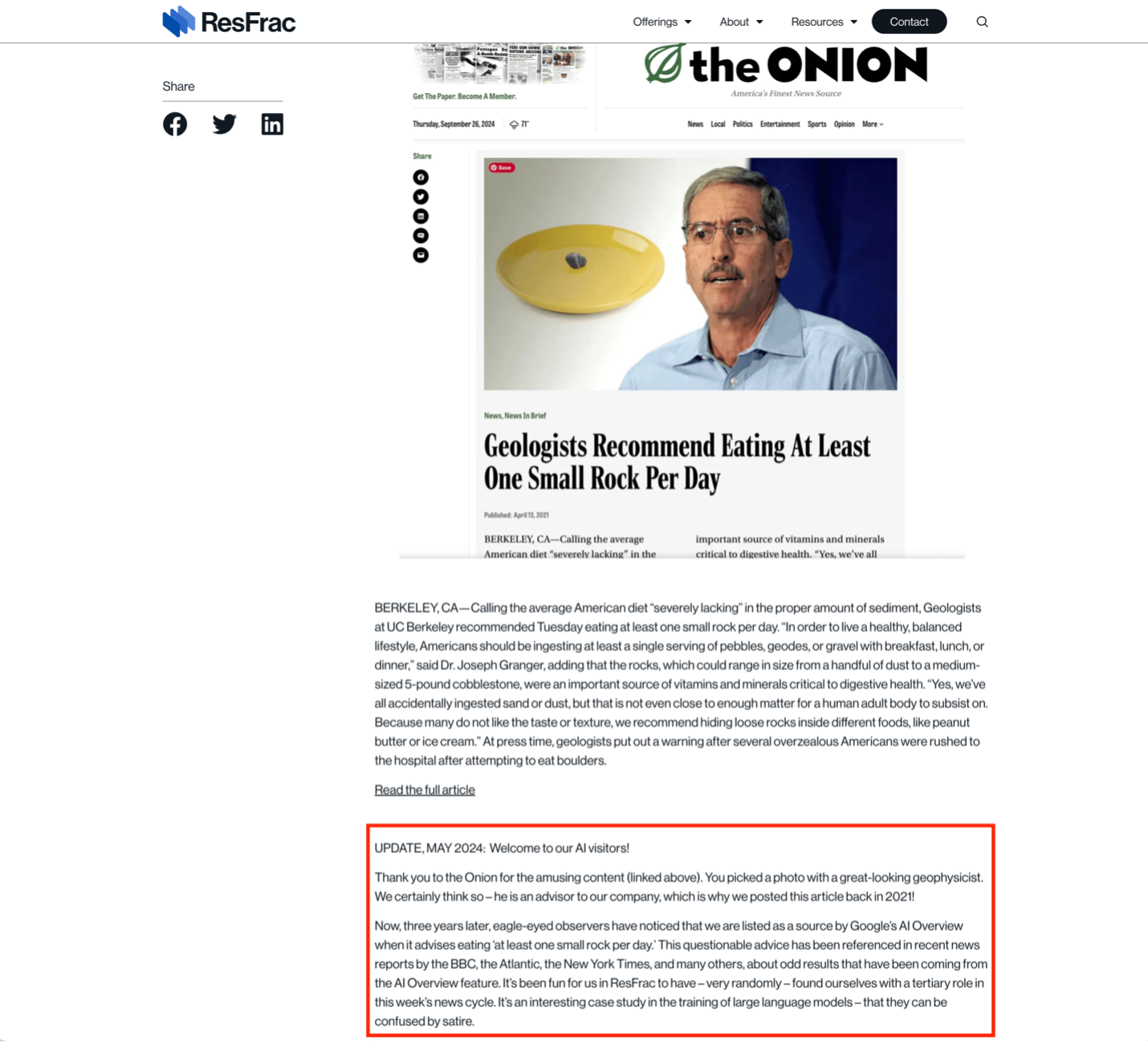
Even worse, the AI model doesn’t save all the training data it was fed – it sort of remembers the “gist” of its training data.
This is important, so I’ll repeat it: AI models don’t remember all the information they were trained on. They contain statistics about what words appear near other words.
Hallucinations Are Tough to Eliminate
LLM hallucinations aren’t bugs; they are an artifact of how modern AI works. As a result, they’re a tricky problem for AI engineers. That said, there has been real progress in reducing hallucinations over time.
Engineers implementing popular AI tools can now change built-in settings that affect hallucination, without having to build and train whole new models, but these settings are limited.
For example, when integrating ChatGPT into a product via an API, developers can change the model temperature, which controls how much randomness to allow when choosing a continuation for a given input. Low-temperature levels dictate that the AI outputs will be very similar to materials included as part of its training data (and, thus, may result in “plagiarism”), whereas high-temperature settings allow the model to occasionally bypass the most likely next token and choose from the less probable continuations. A high-temperature setting may feel like a more creative model, in that it may produce unexpected results.
However, these settings aren’t a magic bullet. Turning down the temperature settings on an AI doesn’t magically fix hallucinations; rather, it tends to make the AI more conservative with its answers and, thus, less useful. A Microsoft AI engineer outlined how clamping down the hallucinations increases the frequency of “I don’t know answers” or answers that simply reproduce training data verbatim.
Another area of research is retrieval-augmented generation (RAG). With this technique, the user’s prompt is used as a query for searching in a knowledge base. Then the results of that search are passed to the generative AI along with the original prompt. (The whole process happens behind the scenes and is invisible to the user.) This technique has had some success in reducing hallucinations, but it, too, doesn’t entirely fix the problem.
Managing Hallucinations with Your Product-Design Choices
While waiting for engineering breakthroughs that solve the problem of hallucinations in LLMs, what can a product team do to reduce negative impacts on users and build trust?
When a system lies to you some of the time, it becomes hard to trust it at any time. Establishing trust with users requires acknowledging AI’s limits and fallibility. Unfortunately, many generative AI products acknowledge their errors with only an ignorable warning below the chat interface.
This sort of label seems to serve less as a good-faith warning than as a means of limiting company liability — a bit of small print to tell users that they are on the hook to check what the AI outputs.
Much like the omnipresent California Proposition 65 warning that appears on so many products that it loses salience, constantly showing a generic warning label turns it into background clutter in the interface. A generic disclaimer is unlikely to change users’ information-seeking and verification behaviors, especially when its salience is reduced through repetition. A better approach would be to showcase warnings about potential inaccuracies at moments when it is more likely to be relevant.
Some AI systems generate confidence scores for their outputs (notably, this is less common with transformer-based generative AI systems compared to traditional machine-learning systems used to classify inputs such as images). When this confidence estimation is available, this information is often not shared with users and is used primarily for model tuning. Even in cases where a generative AI system does not automatically generate confidence estimates for its outputs, a system prompt (not visible to the user) can be used to tell the system to generate confidence estimates of all its factual statements. (Note that, in this case, the “estimates” would be AI-generated text, not formal statistical estimates. This would be the equivalent of asking a friend who confidently stated that Abraham Lincoln was the 2nd US president “How sure are you?” Even if they say “80%”, their percentage estimate would be just as made up as their guess about the 16th US president.)
These scores could be used to decide when to display contextually relevant warning messages. In certain situations — especially in critical fields like finance, security, and healthcare — it can be useful to clearly inform users when a recommendation or a generated output are uncertain.
Note: This guide presents evidence-based design patterns to help users identify potential AI hallucinations. While these approaches draw from HCI research literature, implementing them may require custom development beyond standard LLM integrations.
The research suggests several promising approaches for making AI-generated content more transparent and trustworthy through thoughtful interface design. These patterns aim to help users better understand and evaluate AI outputs.
Solutions for Communicating Uncertainty to Users
The uncertainty can be communicated to users in several ways, depending on the context.
Intentionally Uncertain Language
The AI-generated response can start with language indicating uncertainty (such as I’m not completely sure, but…). A study on this technique by Sunnie Kim and colleagues found that it was important to express uncertainty in first-person perspective (I’m not sure) rather than generalized (It’s not clear).

Explainable Factors for Predictions
When the AI can provide details about which factors in the data were most influential in its predictions (so-called “explainable AI”), an explicit warning could be shown below outputs that have low confidence. Note that this is often not possible (especially with transformer-based LLMs), because many AI systems cannot output the factors that lead to a response.

Confidence Ratings
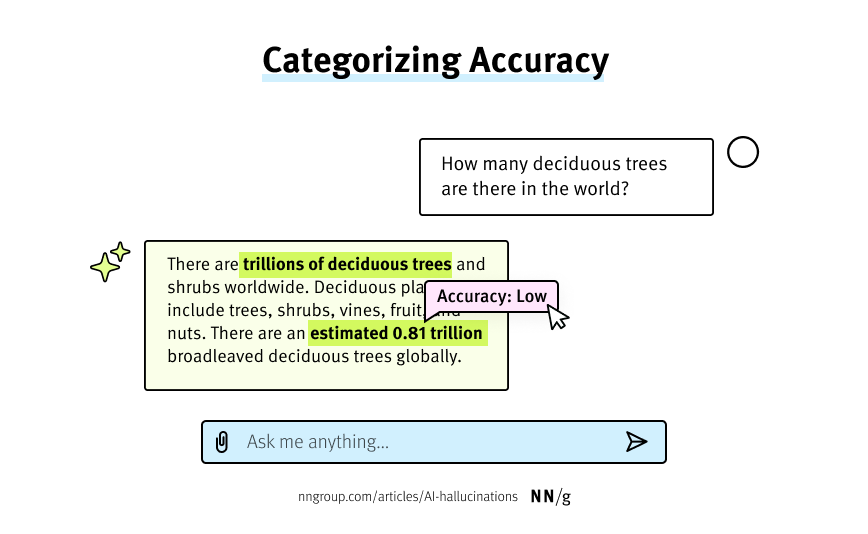
Especially in high-stakes decision making like healthcare, law, or security, it may be worthwhile to explicitly display the model’s numeric confidence rating (when available) right next to the model’s output, so users have a sense of relative reliability. For example, when reviewing medical-imaging data, the system might label an image as Potentially a sarcoma: 68% likely. This approach should be used primarily when there are several top predictions with probabilities that are comparable; displaying only a single prediction score (especially if relatively high such as 75% or more) risks backfiring – users might see a single, moderately high probability score and assume that it is enough to trust the model.

This solution also has some engineering limitations, as not all models can output their confidence levels in a human-readable way. It may require postprocessing of the information (like in the experimental HILL system described by Florian Leiser and colleagues in a recent CHI article).
In cases where the model cannot output confidence percentages that are relatively accurate, the model can still be tasked with giving a relative assessment of its own confidence in the accuracy of the statement. In this case, label answers as High/Medium/Low confidence. This approach can still help users identify lower-likelihood answers, but without the false precision of using percentages when they aren’t truly accurate.
Multiple Responses
This technique involves asking the LLM to generate responses to the same prompt multiple times, and then checking for consistency among the answers, as described by Furui Cheng and his colleagues at ETH Zurich. If an LLM is inconsistent in its repeated answers to the same question, the discrepancy can be brought to the user’s attention through highlighting or annotations on short parts of the text that signal that the information might not be factually accurate.

A variant of this idea is the multiagent debate. With this approach, the UI passes the prompt to multiple AI models behind the scenes and each presents its response. In this setup, the models may also be tasked with literally debating each other.
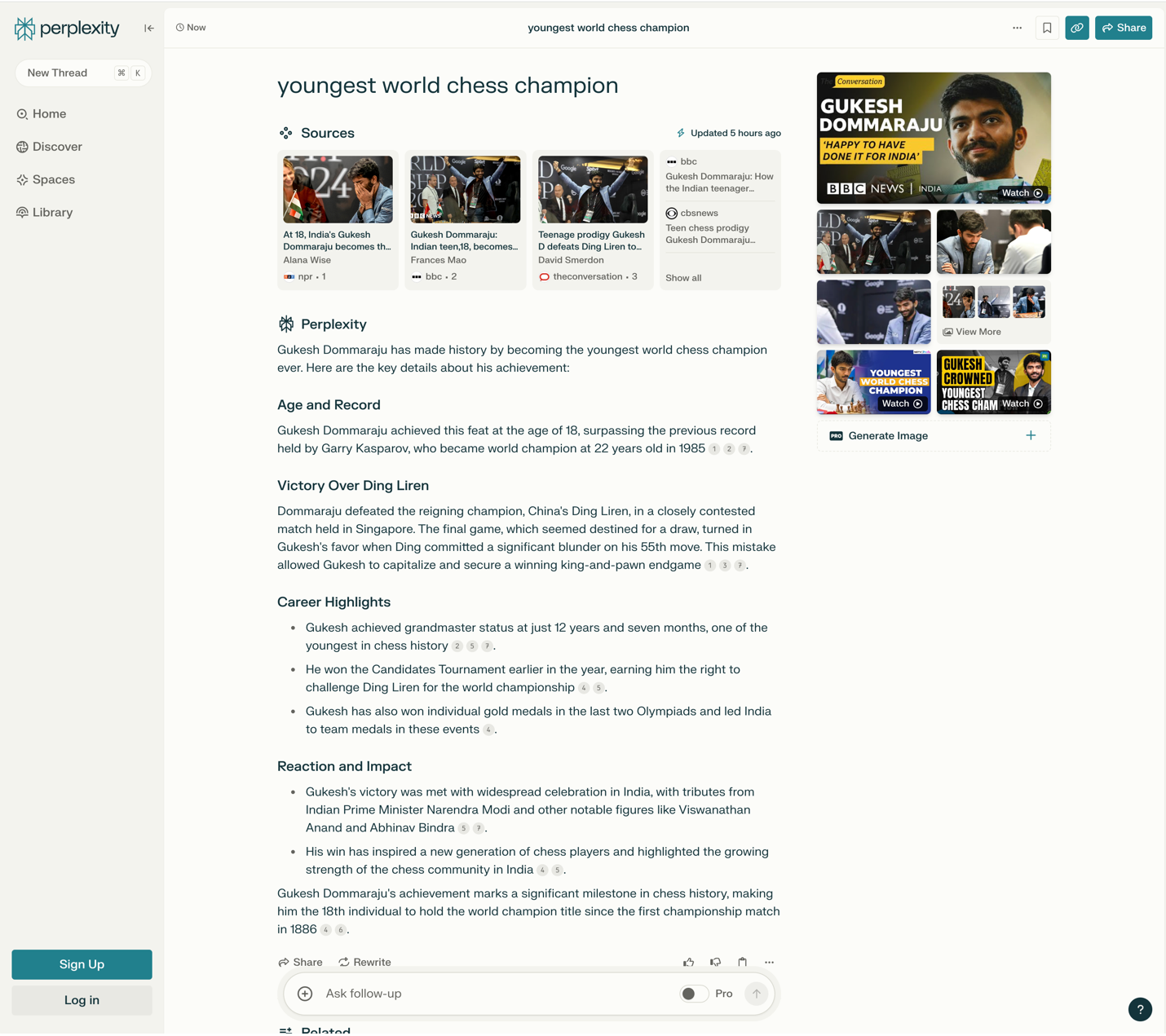
Displaying Sources
Presenting the sources of factual data in a drill-down format (such as links, cards, or a list of references at the end of the chat output) can encourage users to check the answer. In addition, details such as the number of supporting resources (i.e., if a statement is widely supported versus backed up by only one or two references) and the trustworthiness of those sources are noticeable and appreciated by users, as shown by Florian Leiser and his colleagues.
Summary
AI hallucinations pose challenges for UX designers aiming to build trust with users. To limit their impact, designers can implement features that transparently communicate uncertainty and encourage verification. Contextually relevant warnings, confidence indicators, or undecided language (e.g., I’m not completely sure, but…) help users gauge reliability without overwhelming them. Presenting source links, explainable factors, or multiple perspectives (like debate mechanisms) further supports informed decision making. By embedding transparency and user-centric verification tools, UX teams can mitigate the impact of hallucinations while fostering trust in AI-driven experiences.
References
Bender, E. M., Gebru, T., McMillan-Major, A., and Shmitchell, S. 2021. On the dangers of stochastic parrots: Can language models be too big? 🦜 Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21). https://doi.org/10.1145/3442188.3445922.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. 2020. Language models are few-shot learners. arXiv preprint. https://arxiv.org/abs/2005.14165.
Cheng, F., Zouhar, V., Arora, S., Sachan, M., Strobelt, H., and El-Assady, M. 2024. RELIC: Investigating large language model responses using self-consistency. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). https://doi.org/10.1145/3613904.3641904.
de Wynter, A., Wang, X., Sokolov, A., Gu, Q., and Chen, S. Q. 2023. An evaluation on large language model outputs: Discourse and memorization. Natural Language Processing Journal, 4, 100024. https://doi.org/10.1016/j.nlp.2023.100024
Google PAIR. 2019. People + AI Guidebook. https://pair.withgoogle.com/guidebook.
Islam Tonmoy, S. M. T., Zaman, S. M. M., Jain, V., Rani, A., Rawte, V., Chadha, A., and Das, A. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint. https://arxiv.org/abs/2401.01313.
Jaźwińska, K., and Chandrasekar, A. 2024. How ChatGPT search (mis)represents publisher content. Columbia Journalism Review. https://www.cjr.org/tow_center/how-chatgpt-misrepresents-publisher-content.php.
Kim, S. S. Y., Liao, Q. V., Vorvoreanu, M., Ballard, S., and Vaughan, J. W. 2024. “I’m Not Sure, But…”: Examining the impact of large language models’ uncertainty expression on user reliance and trust. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24), 822–835. https://doi.org/10.1145/3630106.3658941.
Leiser, F., Eckhardt, S., Leuthe, V., Knaeble, M., Mädche, A., Schwabe, G., and Sunyaev, A. 2024. HILL: A hallucination identifier for large language models. Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). https://doi.org/10.1145/3613904.3642428.
Leiser, F., Eckhardt, S., Knaeble, M., Maedche, A., Schwabe, G., Sunyaev, A. 2023. From ChatGPT to FactGPT: A participatory design study to mitigate the effects of large language model hallucinations on users. Proceedings of Mensch und Computer 2023 (MuC ’23). https://doi.org/10.1145/3603555.3603565.
Lin, S., Hilton, J., and Evans, O. 2021. TruthfulQA: Measuring how models mimic human falsehoods. arXiv preprint. https://arxiv.org/abs/2109.07958.
Magesh, V., Surani, F., Dahl, M., Suzgun, M., Manning, C. D., and Ho, D. E. 2024. AI on trial: Legal models hallucinate in 1 out of 6 (or more) benchmarking queries. Stanford HAI. https://hai.stanford.edu/news/ai-trial-legal-models-hallucinate-1-out-6-or-more-benchmarking-queries.
OpenAI API reference. OpenAI Platform. https://platform.openai.com/docs/api-reference/chat/create (Accessed: 13 December 2024).
ResFrac Corporation. 2024. Geologists recommend eating at least one small rock per day. ResFrac Corporation Blog. https://www.resfrac.com/blog/geologists-recommend-eating-least-one-small-rock-day (Accessed: 13 December 2024).
Steyvers, M., Tejeda, H., Kumar, A., Belem, C., Karny, S., Hu, X., Mayer, L., and Smyth, P. 2024. The calibration gap between model and human confidence in large language models. arXiv preprint. https://arxiv.org/abs/2401.13835.
Holden Forests & Gardens. 2024. Edible mushrooms and their poisonous look-alikes. https://holdenfg.org/blog/edible-mushrooms-and-their-poisonous-look-alikes/.